


Document Redaction with Scale and Accuracy
In most organizations, reports and documents are originally created for internal use to support decision‑making. However, more and more of these documents now need to be shared with external stakeholders such as partners, subcontractors, and regulatory authorities. This increases the risk of unintentionally exposing sensitive information—such as personal email addresses or signatures—contained within the documents, and ultimately the risk of becoming non‑compliant with regulations like GDPR in Europe or HIPAA, GLBA, or COPPA in the United States.
The solution to avoid this risk is Document Redaction, the creation of a copy of the original document where the sensitive information is hidden in the document.
In the era of Agentic AI, one might assume that redacting sensitive information across large volumes of documents is trivial for a Generative AI model with a well‑crafted prompt. And that’s not entirely wrong: an AI agent powered by generative models can process thousands of pages per hour and correctly identify around 95% of sensitive information—an impressive score for any data scientist working on unstructured‑document extraction.
The problem lies in the remaining 5%. As with any AI accuracy discussion, two issues matter most: recall and precision.
The Recall Issue
Recall measures the ratio of correctly captured values to the total number of values that should be captured. A recall of 95% means that 5% of sensitive information is missing. For example, if an agent with 95% recall processes 100 documents and extracts 1,000 IBAN numbers, you should expect that around 50 IBANs were not detected—and therefore will not be redacted. You can improve the model or refine the prompt and maybe reach 98% recall, which is great. But the real question is: “Is releasing 20 unredacted IBANs acceptable?” If not, what’s the alternative?
The Precision Issue
Precision measures the ratio of true positives to the total number of detected values. A precision of 97% means that 3% of detections are in fact not sensitive information. If your agent is designed to detect phone numbers and identifies 10,000 of them, but 300 are actually well names, dates, or other unrelated values, redacting them will make the document harder to read—or even unusable. So again, what’s the solution?
These two issues clearly show that while AI can be an excellent assistant for document redaction and can really speed up the redaction process, it cannot be trusted to operate at 100% accuracy on its own.
At Agile Data Decisions, we have always believed that achieving true reliability requires a Human‑In‑The‑Loop (HITL) approach. Humans work slower than agents, but they have superior reasoning abilities to detect edge cases, identify errors, and correct them.
Human In The Loop in the Agiledd platform
In the AgileDD platform, the HITL approach covers multiple aspects to ensure complete and trustworthy document redaction. First is the user interface. The AgileDD platform can be summarized with two acronyms: AI + UI. The UI allows users to define search agents, evaluate their performance, and review detected values in detail—validating or rejecting them as needed.
Defining a search agent—called an “attribute” in the platform—is extremely fast. You open a document, highlight an example of the information you want to capture (for instance, a person’s name), give the agent a name, specify the type of data to extract (text, numbers, tables, graphical data, etc.), and the agent is ready to learn. It’s a fully no‑code approach that makes creating an agent as easy as 1‑2‑3!
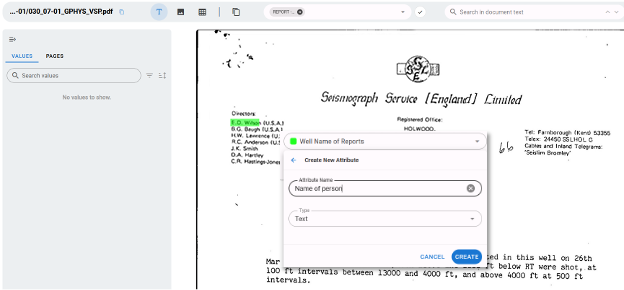
Once the agent is defined, it needs an engine. The platform provides a wide range of AI models—Machine Learning, CNNs, LLMs, and hybrid approaches—to detect the information you’re looking for. You can even combine several models and cross‑check their outputs to minimize recall issues.
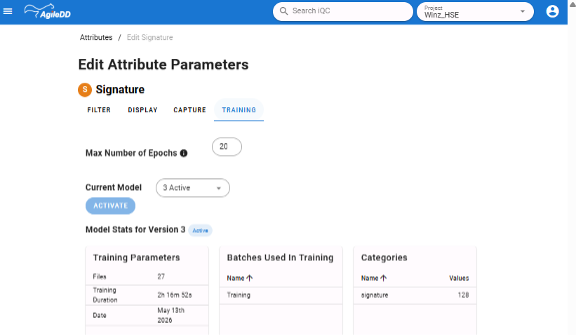
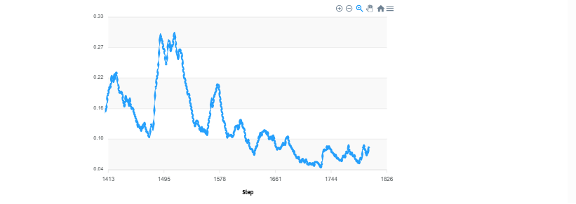
After training the first version of your agent, or after assigning a prompt to it, you’ll likely want to evaluate its performance. Again, the UI makes this easy: it displays precision and recall for supervised models using cross‑validation during training, or precision and recall for any model using a hold‑out evaluation on a benchmark of your choice. The loss curve of the CNN you train is also available, allowing you to verify whether the model has converged.
This information is not only essential for users to understand and trust the models (or sometimes not ☹), but also for implementing proper AI governance.
Now that the agents have been built and evaluated, they can be applied to detect sensitive information across any set of documents—regardless of size or format. On the AgileDD platform the scalability is ensured by a full paralyzed computing running in a Kubernetes™ environment, which automatically allocates the necessary resources at the right time. Format diversity is handled by our preprocessing pipeline, which performs OCR on documents while preserving their original layout.
Once processing is complete, you can access detailed statistics about the detected values directly from the folder page.
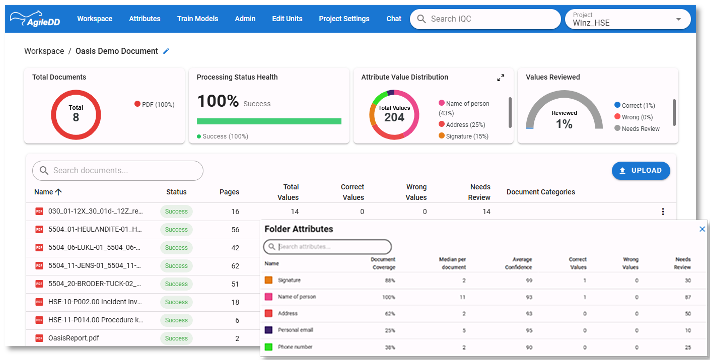
Opening a document allows you to review how sensitive information has been detected and to interact directly with the extracted values. You can delete any false positives (incorrect detections) and highlight missing detections that should be considered for redaction.
You can also strengthen the agent’s training by providing feedback. Any detected value can be validated or marked as incorrect, helping the agent learn and improve over time.
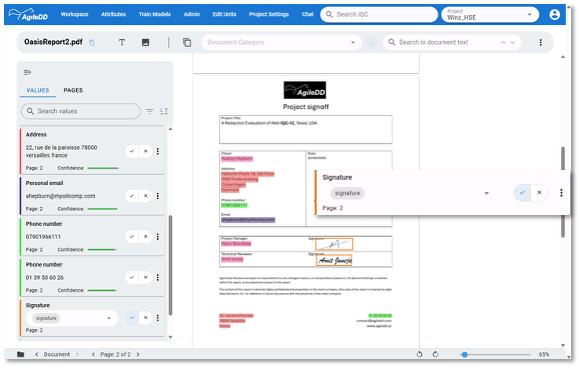
Since it’s so easy to prepare, train, and run an agent to capture sensitive information, why not design several agents for the same target? For example, an address might be detected by an LLM, but also by a traditional NER model. Combining the outputs of both agents increases the overall recall of address detection.

A non reversible redaction
AgileDD agents operating under human supervision can do an excellent job detecting sensitive information, but once the detection is complete, the information must be masked using a non‑reversible method.
Because AgileDD is multimodal, all detections are performed on both the text and graphical modalities of the document. As a result, every captured value is precisely located within the document’s layout. This makes it possible to generate a graphical redaction layer and provide the user with a PDF version of the document that contains only this graphical layer, with the option to include a text layer generated by OCR after the redaction is applied.

Conclusion
Document redaction may appear surprisingly simple at first—especially when using AI to extract information from documents—but its complexity becomes clear very quickly. The challenge is to reliably redact sensitive data so documents can be safely shared while remaining compliant with regulations such as GDPR in Europe or HIPAA in the United States.
The AgileDD platform’s Human‑In‑The‑Loop approach combines the scalability of agentic AI with the high level of compliance ensured by human supervision. For highly sensitive documents, such as medical records, the AgileDD platform demonstrates every day its ability to deliver reliable and highly secure redaction processes.
If you need to minimize the risk of exposing sensitive or personal data when exchanging documents with third parties or the public, feel free to contact us for a demo.