

AI for Document Redaction

Figure 1: A squirrel executing a document redaction before AI emerged…
Today, I’d like to walk you through a task that may seem surprisingly simple at first glance—especially when using AI to extract information from documents—but which quickly reveals its complexity: redacting sensitive data so documents can be safely shared while staying compliant with regulations such as GDPR in Europe or HIPAA in the USA🔒.
At first, it all sounds quite straightforward, but as is often the case with AI, things become a bit more nuanced once you look closer.
On advanced AI platform like AgileDD™, building agents capable of performing OCR and recognizing entities such as phone numbers, email addresses, or signatures is actually fairly easy. With access to a rich ecosystem of machine learning models, computer vision tools, and LLMs, you can quickly design systems that detect sensitive information at scale, processing thousands of documents per hour with impressive efficiency 🚀. Scalability is therefore not a real concern, and for organizations that require the highest level of control, the platform can also be deployed on‑premise, ensuring full security and ownership of both documents and data.
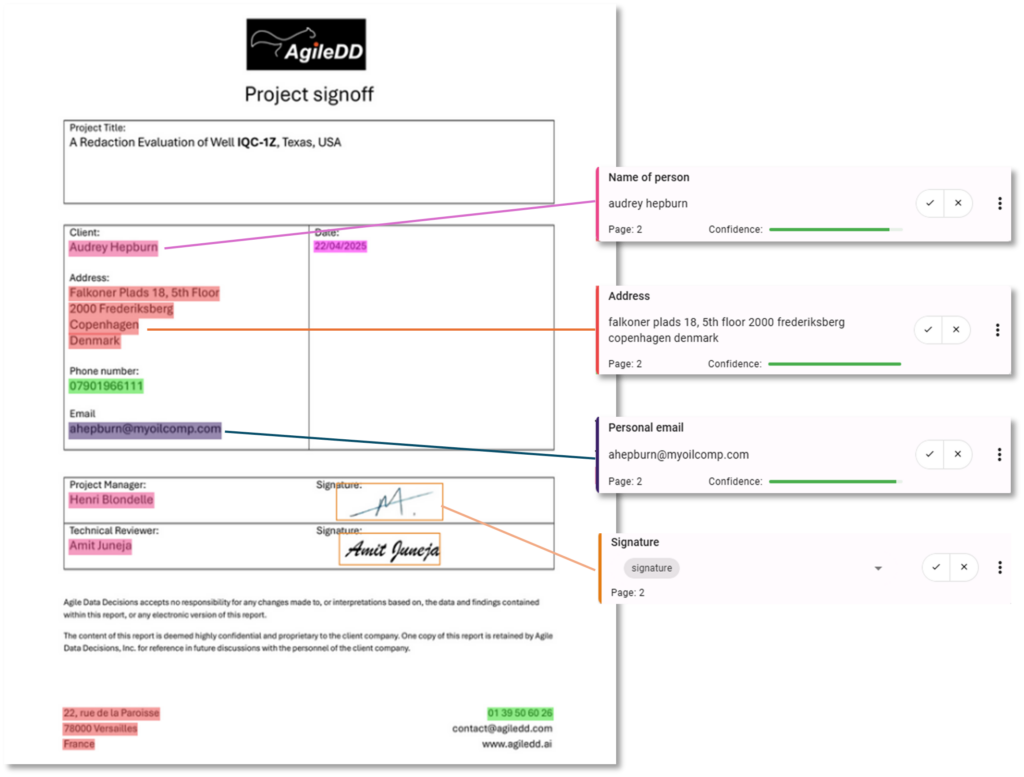
Figure 2: Today squirrel detecting sensitive information using agileDD agents
From a performance standpoint, modern approaches—particularly those relying on CNNs and LLMs—can typically achieve an F1 accuracy of around 95% 📊. At first glance, that level of performance seems more than sufficient, which naturally leads to the question: where is the real problem, and why does it matter?
The answer lies in the remaining 5%, and more importantly, in the risk associated with that small but critical margin, especially when dealing with strict regulatory frameworks. To better understand this, let’s take a closer look at the two main types of risk.
🔴 The risk of false negatives
The most serious issue by far is the risk of missing sensitive information, also known as false negatives.
Imagine an AI system that correctly identifies 12,567 IBAN numbers and their associated account owner names within a large document set, but happens to miss just 4 of them. This corresponds to a 99.97% recall rate, which would undoubtedly satisfy even the most demanding data scientist. However, from a security perspective, those 4 missed entries can already represent a significant exposure.
Now consider a more realistic scenario where recall reaches a still respectable 97%. In that case, the number of missed IBANs is no longer 4, but 377, which dramatically increases the risk. At that point, the conversation shifts completely, and it’s not hard to imagine your data security officer becoming slightly… agitated 😅. This example illustrates why high accuracy alone is not enough when absolute data protection is required.
🟠 The risk of false positives
On the other side of the spectrum, we find the risk of false positives, where the system becomes overly cautious.
For instance, if you instruct an AI agent to mask personal names, it may successfully do so but also end up redacting company names that resemble personal names. The result is often a document that becomes difficult to read, or in some cases even unusable, which defeats the original purpose of sharing it.
🧠 A simple but important reality
Even with excellent performance metrics, an AI solution for detecting sensitive information should be viewed as an extremely fast and valuable assistant, but not as a standalone compliance tool. This distinction is critical when designing reliable workflows.
⚙️ So what’s the right approach?
This is where AgileDD brings a pragmatic answer, built on two complementary principles.
First, the platform provides a wide variety of models and detection techniques, allowing you to combine multiple approaches rather than relying on a single method 🔍. Second, and even more importantly, it integrates a powerful Human‑in‑the‑Loop (HITL) workflow, enabling users to quickly review and validate the suggestions made by AI.
When data security is non-negotiable, this combination proves extremely effective, as it allows organizations not only to reach 100% effective accuracy, but also to track every detection, audit decisions, and continuously improve models over time.
✅ Putting it into practice
In concrete terms, several best practices can be implemented on the platform.
It is highly recommended to begin with benchmarking, by comparing AI results with documents that have already been processed by humans. This helps you understand how the system performs on your own data, which often includes specific challenges such as layout variations, multiple languages, scan quality, or even handwritten content 📄.
Another key approach is to combine multiple detection methods, including RegEx, NER, machine learning models, computer vision, and LLMs. When a piece of information is flagged by one method but not by others, it deserves closer attention, as this discrepancy can reveal hidden risks.
Finally, AgileDD’s interface makes it very easy to validate or reject detections directly within their context, allowing users to ensure 100% reliable redaction while also feeding valuable feedback into the system to improve future processing cycles.
🤝 Combining AI and Human validation
By combining AI efficiency with human judgment, AgileDD enables highly reliable redaction of sensitive documents at scale, ensuring compliance with major regulations such as:
- GDPR in Europe
- HIPAA for the healthcare domain in the USA
- GLBA in financial services
- COPPA for children’s data
This hybrid approach significantly reduces the risk of sensitive information ever being exposed to partners or to the public.
🔒 One last critical point
Beyond detection, it is essential to ensure that the redaction itself is irreversible, as simply hiding content visually is not enough.
Thanks to its multimodal architecture, AgileDD has addressed this requirement from the very beginning, more than 10 years ago 🎯. By combining text detection with graphical-level redaction, the platform ensures that sensitive information is permanently removed and cannot be recovered in any way.

Figure 3: Same page than on figure 2 but with a redaction applied on the phone numbers, personal emails, signatures and addresses. The redaction has not been applied on the detected names of person and functional emails
✅ Final thoughts
At the beginning of this article, I mentioned that document redaction might not be as simple as it seems, and that remains true in practice. However, with the right tools and the right approach, it becomes entirely manageable.
With AgileDD, everything is in place to empower your data scientists while reassuring your security and compliance teams 😊, creating a balanced and reliable workflow.
👋 Want to learn more?
If this topic resonates with you, feel free to reach out—even if it’s just for a quick 10–15 minute demo ⏱️.