

Human in the Loop Doesn’t Limit AI Scalability — It Enables It

Whenever we meet with potential customers or investors, there’s a moment we’ve come to expect. As soon as we start explaining or demonstrating the Human‑in‑the‑Loop (HITL) capabilities built into the AgileDD platform, we notice a few skeptical looks.
The question usually follows immediately:
“Can we really operate at scale if we use a HITL approach in our information‑extraction workflows?”
It’s a fair question.
If AgileDD’s HITL approach were limited to simply highlighting detected information for manual review, the benefit over fully manual extraction would indeed be marginal. You might gain a bit of recall, but the time spent reviewing values would be similar to extracting them manually.
But that’s not how AgileDD works.
AgileDD is designed to process millions of document pages per month, and the reason we can scale is simple: we’ve embedded HITL into every layer of the extraction pipeline — not just in the interactive correction interface.
HITL is a quality layer, not a bottleneck
HITL should never be seen as a drag on scalability. It’s the opposite: HITL is the quality layer that makes large scale automation trustworthy.
And if you need proof that HITL and scale go hand in hand, consider a few well known examples:
Google moderates billions of items using HITL, focusing human attention only on the most sensitive cases.
Tesla trains Autopilot using human validated edge cases — exactly like AgileDD users validate ambiguous figures or symbols in technical documents.
OpenAI improves its models through RLHF — Reinforcement Learning from Human Feedback — which is simply HITL at massive scale.
In other words: HITL is not a limiter. It’s a scaling strategy.
HITL focuses on exceptions, not the entire dataset
In AgileDD, HITL does not mean humans review everything.
Instead, the platform intelligently routes only the most relevant cases for human validation:
Low‑confidence captures
Low confidence doesn’t mean the value is wrong — it means the model encountered a context it hasn’t fully mastered yet. These cases are worth a quick look.
Unexpected detections
If the model identifies something unusual — for example, a wellhead diagram inside a seismic report — the probability of error increases. These are ideal HITL candidates.
Non‑coherent results across models
AgileDD can run multiple models on the same task.
If they disagree, that’s a signal: a human should take a look.
High‑impact values
If you’re evaluating the prospectivity of an area and the extraction shows 56 samples above 500 ppm gold, that could be a breakthrough… or a unit‑conversion error.
Before making a high‑impact decision, reviewing these values directly in the AgileDD UI is simply good practice.
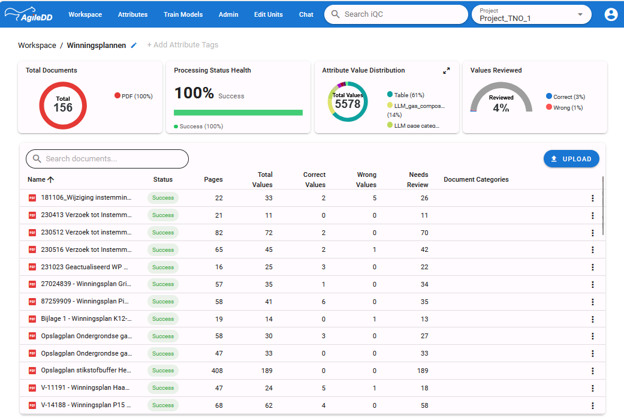
Figure 1 : The folder view illustrates that only 4% of the captured information has been reviewed. It was considered sufficient for the user to trust the other 96%
And, as the cherry on top 🍒, HITL doesn’t just verify critical results—it actively improves detection models. Every human validation becomes a valuable learning signal, helping the system to better understand unusual contexts, and continuously boost accuracy. In other words, the more users interact with HITL, the smarter the AI gets—a virtuous cycle of trust, quality, and ongoing evolution.
HITL accelerates model improvement as data grows
More documents mean more context, more edge cases, and ultimately more opportunities for humans to correct detections and refine prompts or models.
On large datasets, HITL becomes a continuous learning engine for both supervised machine‑learning models and computer‑vision models.
Improving Machine‑Learning (ML) Model
In the era of LLMs, are traditional ML models for keyword or pattern extraction still relevant?
At AgileDD, the answer is yes.
ML‑powered capture agents offer several advantages:
· They are inexpensive to operate.
· They can be trained quickly on a specific document family.
· They respond directly to user feedback.
When a user marks a captured value as correct or wrong, that feedback becomes a direct training signal.
The model improves immediately, without requiring massive datasets or complex fine‑tuning pipelines.
Improving CNN‑Based Computer Vision Models
The same principle applies to agents that detect or classify figures inside documents.
These models can begin performing well with as few as 20 examples per category, and they improve rapidly with HITL validation.
One AgileDD customer uses such an agent to extract geological descriptions from mudlogs.
When the capture is incorrect, the cause is often simple: the layout of the log differs slightly from the training examples.
With HITL, the workflow becomes:
· The user corrects a few examples on the first pages.
· The model is retrained — a process now much faster thanks to AgileDD’s migration to Kubernetes.
· The document is re‑processed.
The result:
The model learns this new layout and becomes fully reliable in that context. HITL transforms a one‑off correction into lasting model improvement.
What about the capture agents powered by a LLM ?
AgileDD allows users to create capture agents powered by LLMs, whether hosted via an external API or deployed on‑premises. We do not train or fine‑tune LLMs directly — but that doesn’t mean these agents are outside human control.
Just like any other extraction:
· LLM‑generated values can be validated
· marked as incorrect
· edited
· deleted
· or replaced with manual captures
And HITL feedback doesn’t stop there.
Validation and refutation can be used to train an additional model that becomes part of the agent — effectively creating a dual‑engine agent where a lightweight supervised model helps the LLM better understand the context in which certain information should or should not appear.
This hybrid approach combines the flexibility of generative AI with the precision and governance of supervised learning.
Cross Validation: Understanding Whether Your Agent Truly Learned
When you train an agent—whether in AgileDD or any other platform—the first question is always the same: Did the model actually learn from the data I provided?
To answer this, AgileDD applies cross validation during training and computes several key performance indicators:
- F1 Score
- Precision
- Recall
- AUC (Area Under the Curve)
These metrics are calculated five times, each on 20% of the training dataset, providing a robust view of model performance. From this process, several insights emerge immediately:
- The higher the F1, Precision, and Recall, the better the model performs. These metrics reflect the model’s ability to correctly identify relevant information while minimizing errors.
- An AUC close to 1 indicates excellent separability between true positives and false positives. In practical terms, it means the model’s confidence scores are meaningful and can be used to filter or prioritize results.
- If F1 scores remain consistent across all folds, the model generalizes well across the entire training context. This consistency shows that the model isn’t overfitting to a subset of the data.
- If F1 scores vary significantly between folds, the model needs more training data to cover all contexts reliably. In other words, the model has learned some situations well but struggles with others.
Cross validation gives users a transparent, data driven understanding of how their agent behaves—before it ever processes a single production document. It’s an essential step for building trust and ensuring that HITL feedback will compound into meaningful improvements over time.
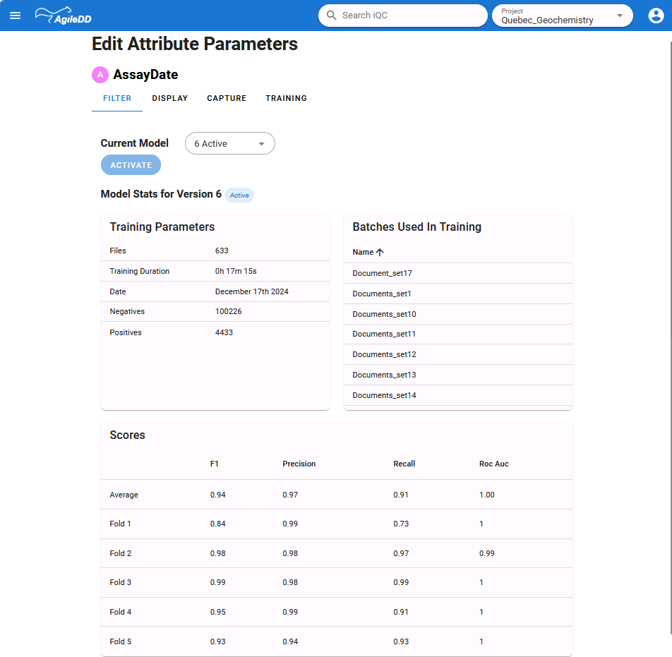
Figure 2: The screenshot above displays the cross-correlation done while training an agent to capture the dates of assays. The training has been done on 4433 correct (positive) values and 100226 additional values have been associated as wrong (negatives) values. With an average precision of 97 and a recall of 91, this model has a good performance. In addition, the F1 score is high on all the folds, It means that the model à good and stable on a large spectrum of documents (contexts).
Benchmarking: Measuring Real‑World Performance on Your Own Data
It’s reassuring to know that a model performs well on documents similar to its training set — and that your data scientist is happy with the metrics.
But the real question is far more practical:
How well will the agent perform on your documents — the ones you actually need to process?
The best way to answer that is simple: run your own benchmark.
Here’s how the process works in AgileDD:
- Upload 1% to 10% of the documents you plan to process. Random selection works best. In many cases, 25 to 50 documents are enough to get a reliable benchmark.
- Run the agent on this subset.
- Validate the results:
- Mark correct captures as correct
- Delete incorrect values, or mark them wrong
- Manually complete missing values
- Run the benchmark.
AgileDD compares the model’s detections with your validated ground truth, counts:
- True Positives
- False Positives
- False Negatives
Then it computes F1, Precision, Recall, and even recommends the optimal confidence threshold for the best F1 score.
If you’re satisfied and trust the agent, you can confidently run it on your full dataset.
If you’re not satisfied yet, simply retrain the model — this time including your benchmark dataset in the training set — prepare a new benchmark, and compute the metrics again.
Repeat until the performance meets your expectations.
All of these steps are guided directly through the UI, allowing you to refine your model in a completely no‑code environment.
Accessing Low‑Confidence Values
Once everything is trained and benchmarked, you may still want to review:
- low‑confidence captures
- unexpected detections
- edge cases that deserve a second look
AgileDD’s Advanced Search makes this effortless.
You can filter documents that contain:
- values below a chosen confidence threshold
- detections flagged as unexpected
- specific anomalies or outliers
This allows you to focus your attention exactly where it matters — without manually scanning thousands of pages.
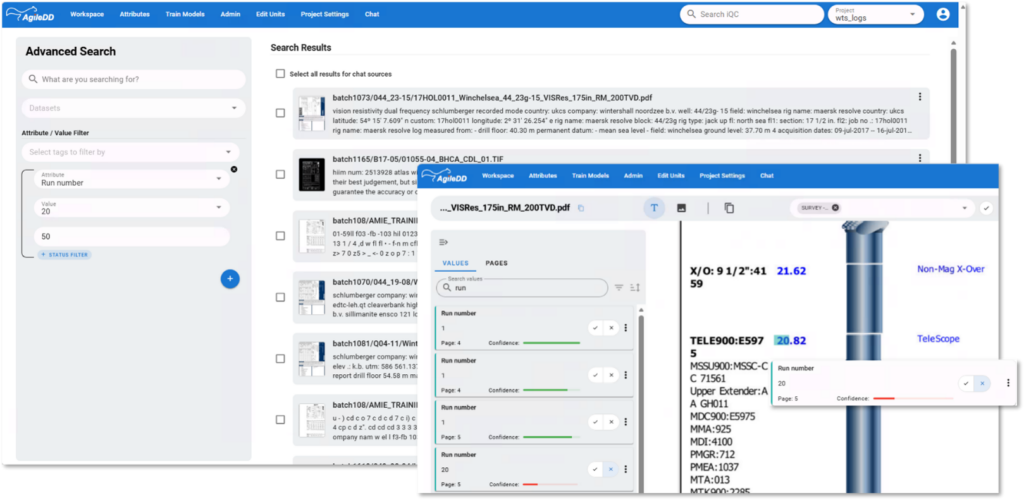
Figure 3: Detection of suspicious values. The user has selected the run numbers with a value of 20, a possible but not frequent value, which has a confidence score below 50. The list of documents having such a run number are displayed and the user has marked this value as wrong to improve the next version of the model.
Conclusion: Scaling With Confidence, Learning With Every Document
Human‑in‑the‑Loop isn’t a constraint on automation — it’s the mechanism that makes large‑scale, high‑quality automation possible. By combining model‑driven extraction with targeted human validation, AgileDD turns HITL into a strategic advantage: a way to scale faster, improve continuously, and maintain full trust in the results.
As your dataset grows, your models grow with it. As your models improve, HITL becomes more selective. And as HITL becomes more selective, your teams can process millions of pages with confidence, knowing that every correction strengthens the system for the next run.
Whether you’re training ML models, refining CNN‑based vision agents, validating LLM‑powered extraction, or benchmarking performance on your own documents, AgileDD provides a no‑code environment where every interaction contributes to a smarter, more reliable AI pipeline.
In a world where accuracy, transparency, and governance matter as much as speed, AgileDD proves that the most scalable AI systems are not the ones that remove humans — but the ones that empower them to guide, correct, and elevate the technology.
If you’d like to see how AgileDD can transform your document workflows, we’d be delighted to show you a live demo.
Reach out to our team — and discover how HITL‑powered automation can help you scale with confidence.